
Flagship Project
CivicAI
An AI-powered municipal by-law assistant built to make long-form by-law documents searchable, explainable, and easier to interact with through retrieval-augmented generation, vector search, and asynchronous document processing.
Project Overview
Building a full-stack AI system for municipal document intelligence
CivicAI is a full-stack AI system that enables users to ask natural language questions about municipal by-law documents and receive structured, citation-backed answers. The system combines retrieval-augmented generation (RAG), vector search, and a scalable asynchronous processing pipeline to support real-world document workflows.
Role
End-to-end builder
System Type
Full-stack AI application
Focus
Municipal document intelligence
Pipeline
Async RAG + vector search
Storage
PostgreSQL + pgvector + S3
Infra
Redis, Celery, Docker, AWS
Problem
Municipal by-law documents are often long, dense, and difficult to search efficiently. Users may know what they want to ask, but not where that information is located inside a PDF. Traditional keyword search is limited, especially when users ask natural-language questions or need context-aware, source-backed answers rather than exact phrase matches.
Solution
CivicAI was built as an AI-powered municipal by-law assistant that combines retrieval-augmented generation with vector search and a background processing pipeline. Instead of relying only on surface keyword matching, the system processes uploaded by-law PDFs, stores embeddings in pgvector, and retrieves relevant passages to support explainable, citation-backed answers through a chat interface.
Architecture
CivicAI is built as a layered system combining frontend interaction, backend APIs, asynchronous processing, and retrieval-based AI workflows.
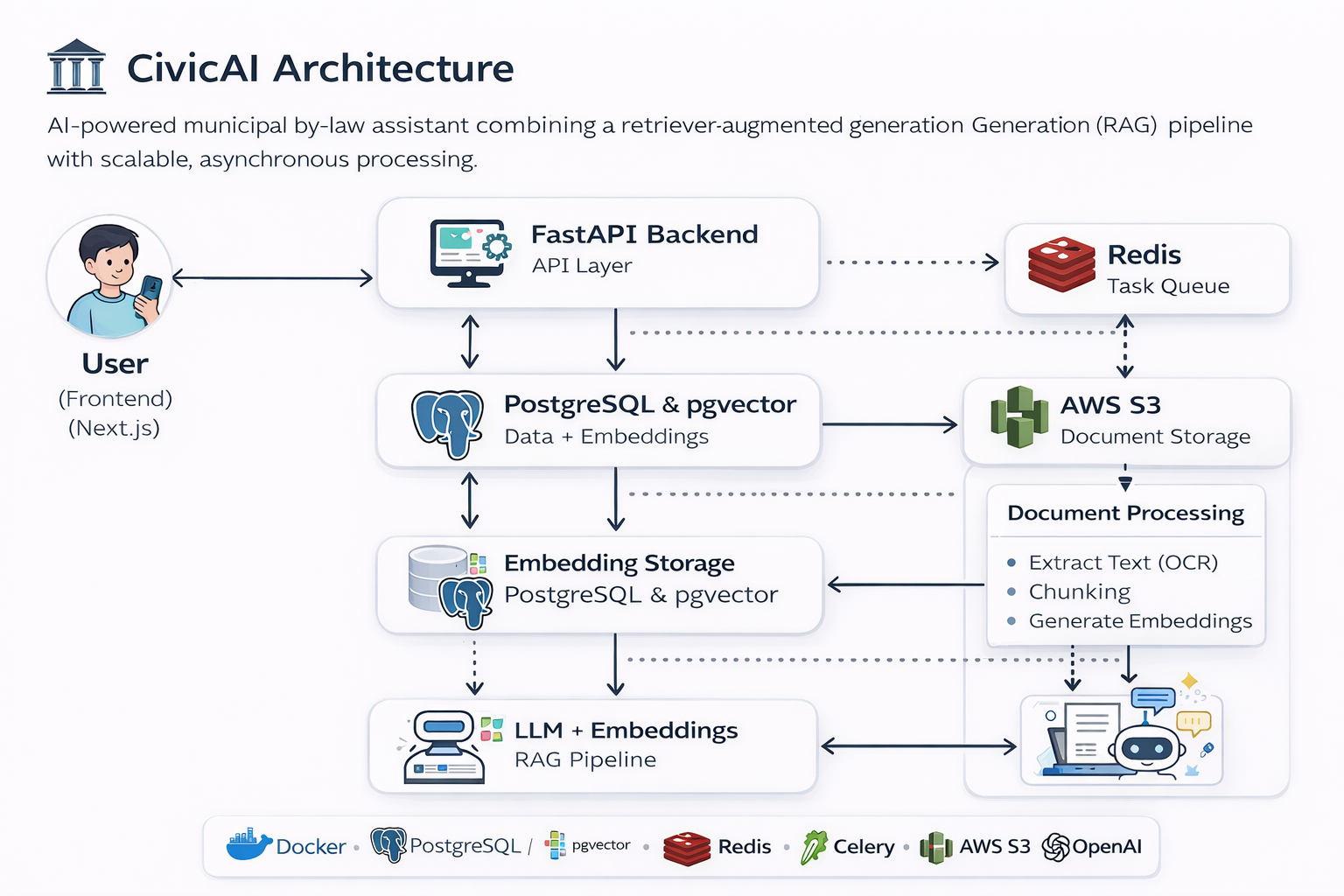
The frontend provides a clean chat-based experience for asking by-law questions. FastAPI exposes backend services for document management, answering workflows, and admin operations. Redis and Celery manage asynchronous jobs, while documents are stored in S3 and embeddings are stored in PostgreSQL with pgvector for semantic retrieval.
Processing Workflow
CivicAI uses an asynchronous document pipeline so uploaded files can be processed in the background before becoming searchable.
This workflow makes the platform more scalable and production-oriented. Instead of processing everything synchronously, jobs move through a queue and are handled by workers, allowing the application to support larger document sets and clearer job tracking.
Key Features
Natural language question answering over municipal by-laws
Citation-backed responses with page-level grounding
Admin dashboard for city and document management
Asynchronous processing using Redis and Celery
Vector search using pgvector for semantic retrieval
OCR fallback support for scanned PDF documents
Job Lifecycle
ProcessingJob
Document
Challenges
One of the key challenges was designing a reliable asynchronous processing pipeline that could handle document ingestion, OCR, chunking, and embedding without blocking the main application flow.
Another challenge was ensuring retrieval quality. The effectiveness of the system depends heavily on how documents are chunked, embedded, and stored, which required careful iteration to improve answer relevance and accuracy.
Building CivicAI as a production-style system also required thinking beyond models — focusing on APIs, job lifecycle management, infrastructure, secure deployment, and the admin workflows needed to manage cities and document sets.
Security & Deployment
CivicAI was deployed with a layered infrastructure approach using Docker, AWS EC2, Nginx, and Cloudflare. S3 is used for document storage, while Cloudflare and Nginx help secure and route traffic to the application.
The system uses HTTPS, reverse proxy architecture, environment-based configuration, and secure API communication between frontend and backend services to support a more deployment-ready setup.
Results
Outcome
Built a complete full-stack AI application that demonstrates municipal document question answering, async document processing, admin-managed ingestion, semantic retrieval, and deployment-aware engineering.
Technical Value
Strengthened hands-on experience across RAG architecture, vector search, asynchronous systems, deployment infrastructure, and full-stack AI application design.
What I Learned
CivicAI reinforced the importance of treating AI products as systems rather than isolated model demos. Building useful AI applications requires strong coordination between document ingestion, retrieval quality, job execution, API design, infrastructure, and user-facing experience. This project strengthened my approach to building AI tools that are not only technically interesting, but also architecturally practical and deployable.